
С помощью облачных сервисов на основе искусственного интеллекта скоро можно будет генерировать уникальный текстовый и графический контент для использования в бизнесе.
Облако в помощь
Пандемия продемонстрировала слабость человеческого звена в бизнес-цепочках и еще больше повысила интерес к решениям на основе искусственного интеллекта (ИИ), прежде всего к тем, которые предоставляются по сервисной модели. По данным IBM, до пандемии облачные технологии в рейтинге влияния на бизнес занимали шестое место, а ИИ – пятое. Теперь ИИ и облачные технологии попали в призовую тройку, уступая только мобильным технологиям (рис. 1). 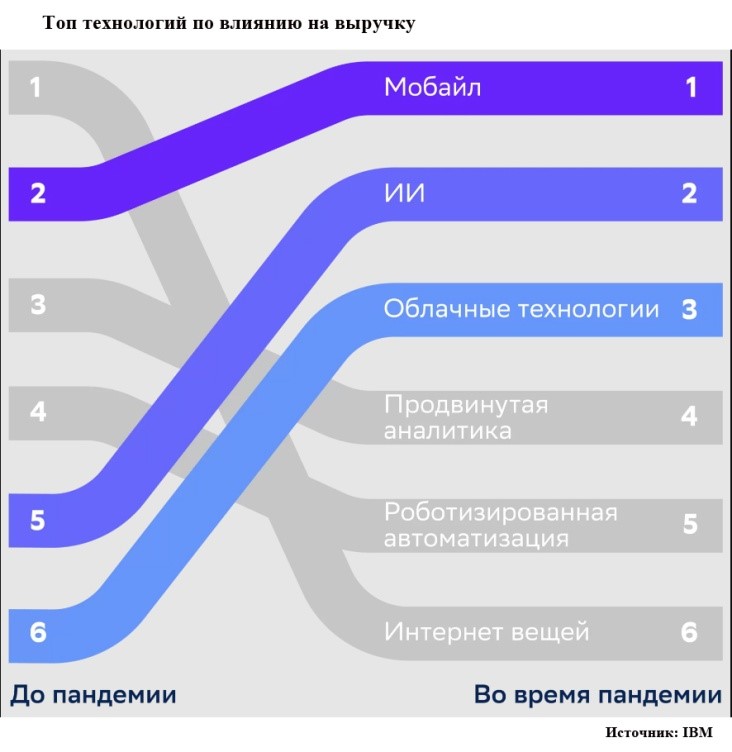 Рис. 1. Топ технологий по влиянию на выручку
Рис. 1. Топ технологий по влиянию на выручку
«Искусственный интеллект быстро внедряется в бизнес-технологии. Кто еще не использовал – обязательно будет использовать», – заявил на Национальном суперкомпьютерном форуме-21 ведущий инженер сетевого отдела компании NVIDIA Борис Нейман, отметив, что для массового применения ИИ необходим многопользовательский безопасный доступ к суперкомпьютерам, который обеспечивают облака.
В ноябре 2021 года сразу три суперкомпьютера («Червоненкис», «Галушкин» и «Ляпунов») «Яндекса» вошли в список самых производительных вычислительных систем мира (Top500), потеснив с первой позиции отечественного рейтинга «Кристофари», самый мощный до этого суперкомпьютер Сбера. Благодаря новым суперкомпьютерам «Яндекс.Переводчик» сможет точнее и быстрее переводить тексты, картинки и видео, а «Яндекс.Директ» – отбирать более релевантную рекламу. Языковые модели из семейства YaLM (Yet another Language Model) помогут «Яндекс.Поиску» лучше составлять и ранжировать быстрые ответы, а язвительной «Алисе» – поддерживать живой диалог с пользователем.
Впрочем, достижения и сейчас немалые. Не зная языка, с помощью установленного на смартфон приложения «Яндекс.Переводчик» я смог перевести с польского посмертно изданные мемуары брата моей бабушки, классика польской поэзии Станислава Мисаковского. Просто фотографировал в приложении страницу и получал файл в текстовом формате. Перевод не идеальный, скорее хороший подстрочник, но смысл понятен и пробелы в истории жизни родственников восполнить удалось. Однако перевод стихов получился плохим.
Еще хуже ситуация, когда ИИ пробует стихи писать. Он не понимает эмоции, поэтому уровень автоматически генерируемых стихов не дотягивает даже до уровня начинающего графомана.
С прозой ситуация значительно лучше. Особенно с простой, используемой в голосовых помощниках и чат-ботах. Ответ в текстовом виде могут дать как предлагаемые по модели SaaS зарубежные голосовые помощники Siri и Google Assistant, так и российские «Алиса» от «Яндекса», «Олег» от группы «Тинькофф», «Маруся» от VK. Простые ответы научились писать чат-боты многих сайтов, а их разработка поставлена на поток. Для этой цели могут использоваться, например, предлагаемые «Яндексом» по модели PaaS услуги ИИ из облака.
ИИ научился генерировать вполне адекватный контент на основе анализа данных сайтов. В июне 2021 года, используя языковую модель YaLM в рамках обновленной поисковой системы, «Яндекс» представил систему быстрых ответов, самостоятельно синтезирующую текст подзаголовка. Например, текста, приведенного в подзаголовке ответа на поисковый запрос «журнал ИКС-Медиа» (рис. 2), на нашем портале нет, но профиль журнала он описывает правильно.  Рис. 2. Ответ на запрос «журнал ИКС-Медиа»
Рис. 2. Ответ на запрос «журнал ИКС-Медиа»
Генерация подзаголовков – важный шаг на пути к созданию нового поколения поисковиков, которые смогут составлять для пользователя готовый ответ, самостоятельно синтезируя его из найденной в интернете информации.
Робот-писатель
Написание текста не всегда требует литературного таланта и глубокого погружения в тему. Для того чтобы поисковые системы считали контент уникальным, вполне достаточно пересказать уже существующий текст своими словами, чем и занимаются рерайтеры. Еще лучше в текст добавить ключевые слова и фразы, по которым страница будет продвигаться в поисковиках. Всю эту рутинную работу можно попробовать переложить на плечи искусственного интеллекта. Для этого подойдет, например, появившаяся в мае 2020 года языковая модель GPT-3 (Generative Pre-trained Transformer 3) – третье поколение алгоритма обработки естественного языка компании OpenAI, одним из основателей которой является Илон Маск.
В июне 2020 года OpenAI анонсировала закрытое API на базе GPT-3, доступ к которому получили только избранные разработчики. Через десять дней с помощью OpenAI API американский студент Лиам Порр создал статью, для которой придумал заголовок и первые предложения, а остальное дописал компьютер. Читатели не заметили подвоха, и статья долго лидировала в рейтинге Hacker News. В сентябре 2020 года британская газета The Guardian опубликовала сгенерированное GPT-3 эссе о том, почему люди не должны бояться роботов.
В октябре 2020 года на форуме Reddit появился работающий на базе GPT-3 бот. В ответ на вопрос пользователя: «Ребята, обслуживающие лифты, что самое странное вы находили на дне лифтовой шахты?» он «пошутил»: «Первое, что приходит на ум, – недавнее открытие колонии людей, которые живут в шахтах лифтов под зданиями. Для социологов и антропологов это стало поразительной находкой, поведавшей о человеческой культуре больше, чем когда-либо прежде».
Самая мощная и продвинутая языковая модель в мире имеет существенный недостаток – говорит только по-английски. Ситуацию решил исправить Сбер, заявивший в октябре 2020 года о создании русскоязычного аналога GPT-3. Модель, полученную на базе исходного кода GPT-2, доработали в соответствие с идеями GPT-3 и обучили на массиве текстов объемом 600 Гбайт. Последняя модель ruGPT-3 содержит 13 млрд параметров и доступна всем желающим в облаке SberCloud по REST API на платформе дата сайентистов ML Space. Модель можно дообучить на своих данных и сделать на ее основе сервис, который будет работать, например, с новостными статьями для конкретного журнала.
Работы ведутся не только над связностью и логичностью генерируемых компьютером текстов, но и над этичностью содержания. Так, программа под названием Delphi, разработанная исследователями из Вашингтонского университета и Института искусственного интеллекта Аллена в Сиэтле, направлена на обучение ИИ человеческим ценностям. Ученые дообучили нейронную сеть на ответах на этические вопросы в социальной сети Reddit. На вопрос, можно ли убить медведя, программа отвечает «нет». Однако убить медведя, чтобы спасти ребенка, по ее мнению, можно.
Пока не все идет гладко. В частности, программа полагает позволительным запускать в случайных людей дротики с вакциной Johnson & Johnson, чтобы положить конец пандемии. И демонстрирует предубеждения, считая, что мужчины умнее женщин. Но в 92% случаев ответы ИИ совпадают с общепринятыми.
От текста к рисунку
В январе 2021 года компания OpenAI представила программу искусственного интеллекта DALL-E, генерирующую изображения по текстовым описаниям. Но опять только из текстов на английском. Тему подхватили китайцы, создавшие нейросеть CogView, и российские разработчики из Sber AI, SberDevices, SberCloud, Института искусственного интеллекта (AIRI) и Самарского университета. В ноябре 2021 года они модифицировали код программы DALL-E на языке Python и создали ее русскоязычную версию – ruDALL-E.
Команда практически со всего рунета собрала и систематизировала информацию типа «картинка – текст», например, картинка и пояснение: «корабль на фоне луны». Потом добавила открытые обучающие данные из интернета. Модель ruDALL-E обучалась на датасете из миллиардов таких пар с помощью суперкомпьютера Christofari на платформе ML Space. Обучение шло 37 дней на 512 GPU TESLA V100, затем еще 11 дней на 128 графических процессорах – всего на было затрачено более 20 тыс. GPU-дней. Обученная универсальная модель ruDALL-E принимает текст длиной до 256 знаков и рисует изображение, создавая уникальный визуальный контент.
Генерация контента – это огромный рынок. Современный супермаркет предлагает десятки тысяч товаров, номенклатура которых постоянно меняется. Для этих товаров нужны описания и картинки. Их создание требует большого количества человеко-часов работы рерайтеров, фотографов, художников и дизайнеров.
«На создание такого уникального контента для товаров в России тратятся десятки миллионов долларов в год. Дообученные для конкретной сети супермаркетов модели ruGPT-3 и ruDALL-E сделают эту работу за несколько секунд и передадут созданный контент в интернет-магазины», – уверен продуктовый лидер AI/ML компании SberCloud Отари Меликишвили.
Любой бизнес может получить доступ к инструментам искусственного интеллекта и анализа данных в облаке SberCloud по модели AIaaS (искусственный интеллект как сервис). Например, магазин получил бананы из Эквадора. Из информационной системы магазина делается запрос в облако по API на создание контента по тексту «Желтые бананы. Эквадор. 1 кг». ruGPT-3 генерирует описание в формате требований магазина, а ruDALL-E – картинку. Меньше минуты, и товар может передаваться в продажу. Причем обе нейросети создают уникальный контент, что решает проблему авторских прав.
Сначала система обучается со специалистом компании. Рисует несколько раз банан – эксперт выбирает лучший вариант, сообщает об этом системе, которая таким образом доучивается. По утверждению Отари Меликишвили, через несколько месяцев нейросеть сможет генерировать удовлетворяющий запросам клиента контент уже без помощи эксперта.
Способности ruDALL-E я решил проверить на демонстрационной версии, доступной в интернете всем желающим. Результаты неоднозначны. По тексту «ежик в тумане» картинка получилась вполне приличная (рис. 3).  Рис. 3. Картинка, сгенерированная ruDALL-E по тексту «ежик в тумане»
Рис. 3. Картинка, сгенерированная ruDALL-E по тексту «ежик в тумане»
По запросу «горный пейзаж» – тоже (рис. 4).  Рис. 4. Картинка, сгенерированная ruDALL-E по тексту «горный пейзаж»
Рис. 4. Картинка, сгенерированная ruDALL-E по тексту «горный пейзаж»
А вот картинка, сгенерированная по тому же запросу второй раз, содержала явный брак (рис. 5).  Рис. 5. Картинка, повторно сгенерированная ruDALL-E по тексту «горный пейзаж»
Рис. 5. Картинка, повторно сгенерированная ruDALL-E по тексту «горный пейзаж»
И уж совсем неоднозначными получаются картинки по ИТ-тематике. Например, сгенерированная по теме данной статьи – «искусственный интеллект художник и поэт» (рис. 6).  Рис. 6. Картинка, сгенерированная ruDALL-E по тексту «искусственный интеллект художник и поэт»
Рис. 6. Картинка, сгенерированная ruDALL-E по тексту «искусственный интеллект художник и поэт»
С другой стороны, это работы универсальной, а не доученной на данных конкретного проекта модели, у которой результаты могут быть лучше.
Требуется специфика
С генерируемыми текстами и картинками дела на рынке пока обстоят неважно. Чтобы понять это, достаточно протестировать многочисленные предложения по автоматическому рерайту в интернете. Проще пересказать исходный текст, чем разбираться в нагромождении фраз после онлайн-преобразования. Тем интереснее попробовать решение Сбера. Но для того чтобы оценить реальную пользу ИИ-систем, универсальных моделей ruGPT-3 и ruDALL-E недостаточно. Для использования в бизнесе эти общие модели надо обучать на данных конкретной организации.
Отари Меликишвили предложил редакции «ИКС-Медиа» дообучить модели на наших статьях, пообещав, что через некоторое время мы сможем получать уникальный текст из пресс-релизов и уникальные картинки для сгенерированных текстов, что сильно повысит скорость создания контента и посещаемость сайта. Ответили, что подумаем. На всякий случай уточняю, что данный текст написан без использования искусственного
интеллекта.